AI-Ready Data Series — Part 2
In the first article, we made one point very clear: AI adoption doesn’t fail because models are weak. It fails because the answers are unreliable, untraceable, and unsafe to use in real decision-making.
That leads to the next practical question: what makes data “AI-ready” in day-to-day business reality? Not in theory. Not in a lab. In organisations where data lives across systems, teams, and tools.
One of the strongest messages from Lukas Zimmermann’s session (Strategy) at our recent AI Success Starts with AI-Ready Data event was that “AI-ready data” is not just about cleaning or moving data to a new platform. It’s about giving AI (and people) the missing business context, consistently, securely, and at scale.
And that is exactly where a semantic layer becomes a game-changer.
The real AI problem most organisations still have
Most enterprises are not one system. They are a patchwork:
- Multiple source systems (ERP, CRM, finance tools, operational apps, spreadsheets),
- Multiple analytics tools (Power BI, Qlik, Tableau, Excel, notebooks),
- Multiple teams defining metrics in parallel.
This creates a familiar kind of “structured chaos”: dashboards that look professional, but don’t agree; reports that are hard to reconcile; and definitions of key metrics that quietly drift over time.

In that environment, AI does not “fix” the mess; it accelerates it.
Because once you connect GenAI to fragmented, inconsistent, loosely governed data, you don’t just risk wrong answers. You risk:
- confident wrong answers (the most dangerous kind),
- unexplainable answers (no traceability),
- unsafe answers (privacy and access rules bypassed in practice).
So “AI-ready data” doesn’t stop at clean pipelines and governed access.
It also requires a controlled layer where business meaning and rules stay consistent across reports, dashboards, and AI use cases.
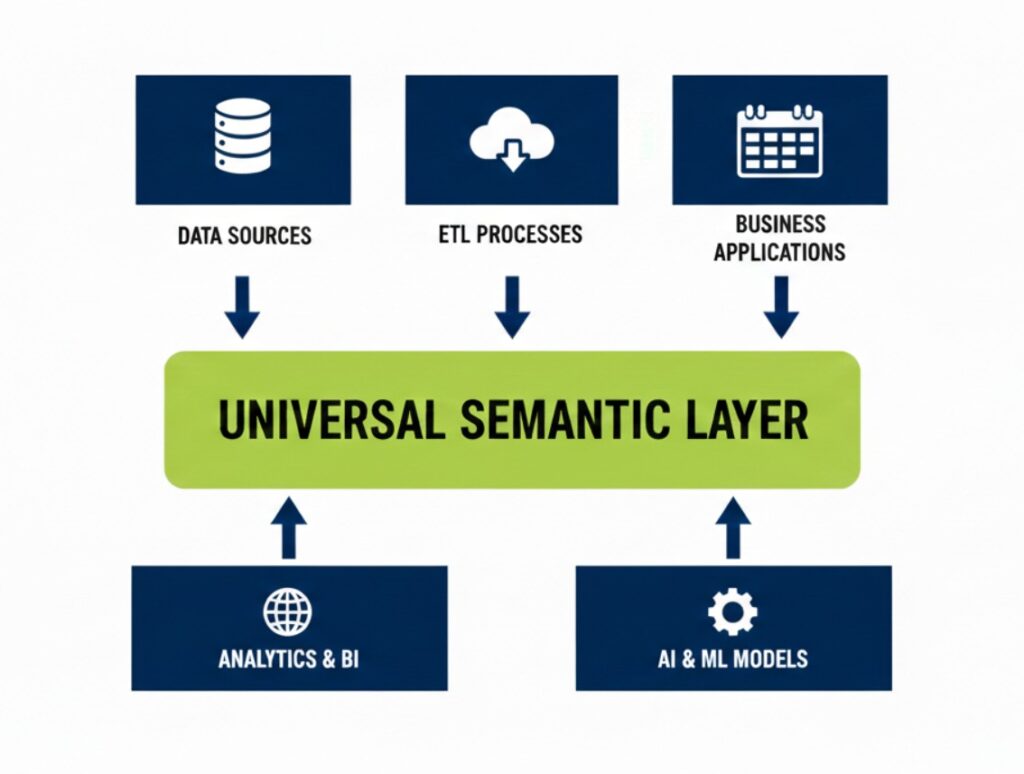
What a semantic layer actually does (in plain language)
A semantic layer is best understood as a governed translation and control layer between your data and the tools (or AI) that use it.
It does six practical things extremely well:
- Turns technical complexity into business language
It maps tables, joins, columns, and system-specific structures into concepts the business recognises (Revenue, Customer, Product, Region, Margin) with definitions that are not open to interpretation. - Creates a single source of truth for metrics
If “Revenue” is defined once with the correct inclusions/exclusions, every tool and every user works from the same definition. - Provides universal access across tools
Instead of each tool building its own logic, multiple tools can consume the same semantic definitions (BI tools, Excel, Python/R workflows, and increasingly AI-driven interfaces). - Enforces governance and security centrally
Access becomes policy: who can see what, consistently, even when new interfaces (like GenAI) enter the picture. - Improves performance and cost predictability
By reducing redundant logic and avoiding duplicated query patterns, teams get more stable performance and fewer “surprise” cost spikes. - Reduces vendor lock-in and increases agility
Tech stacks change. A semantic layer helps maintain stable business definitions as technologies evolve.
If Part 1 was about why data readiness matters, Part 2 is about the mechanism that operationalises readiness: semantic consistency + governance.
“But we already have ETL and a data warehouse — isn’t that enough?”
ETL/ELT and data warehousing are essential. They make data available, structured, and often cleaner. But they typically do not solve these problems well:
- Business definitions live in too many places
A calculation might exist in Power BI, another version in Excel, and a third version in a SQL view. - Security rules are implemented inconsistently across endpoints
Row-level access may be set in one tool, differently in another, and bypassed in ad hoc extracts. - AI needs context that isn’t in the table schema
GenAI doesn’t just need “columns”. It needs meaning: what is official, what is trusted, and what is restricted.
A semantic layer doesn’t replace ETL. It sits above it and answers:
“What does this data mean for our business, and how should it be used safely?”
Why semantic layers matter even more in the GenAI era
With classic BI, a user builds a dashboard, learns the tool, and usually follows some governance process.
With GenAI, the interaction changes:
- users ask questions in natural language,
- tools generate queries dynamically,
- outputs can look authoritative even when logic is wrong.
A semantic layer helps GenAI in two critical ways:
- Accuracy through context
If business definitions and relationships are centrally modelled, AI has a stable structure to reason over. - Trust through governance
If access controls and approved metrics are enforced centrally, AI can’t “accidentally” expose restricted data or redefine KPIs on the fly.
That is the difference between “AI that can talk to data” and AI you can use in real business decisions.
A practical path to “semantic + AI-ready” (without boiling the ocean)
Most organisations shouldn’t try to model everything on day one. We suggest a better approach:
- Start with the metrics that create the most friction
Pick a domain where disagreements are costly: revenue, margin, customer profitability, ESG metrics, risk indicators, or regulatory reporting. - Define and approve a business glossary
Make definitions explicit, documented, and owned (Finance/Controlling + IT + data owners). - Model those definitions once and reuse everywhere
Build a semantic model that tools can consume consistently, instead of rewriting logic per dashboard. - Implement access control in the same layer
Keep governance in place so it can’t be bypassed when new interfaces appear (including AI). - Pilot with real users and real decisions
Success is not “a working demo”. Success is fewer reconciliations, faster close, less debate over numbers, and traceable answers. - Scale domain by domain
Expand in manageable steps, not tool by tool.
Conclusion: AI needs meaning, not just data
AI-ready data is not only about clean pipelines and modern platforms. It’s about shared business meaning and enforceable rules.
A semantic layer is one of the most effective ways to create that foundation. It makes metrics consistent, governance practical, and AI outputs far more reliable — because the model no longer has to guess what your business terms mean.
Next step
If your organisation is experimenting with copilots or AI-driven analytics, but still struggles with inconsistent KPIs, scattered definitions, or governance gaps, it’s usually a sign that business meaning isn’t centralised.
CRMT helps organisations design AI-ready environments by aligning data quality, semantic consistency, governance, and tool architecture so AI becomes reliable enough for real decisions.
If you’d like to explore what a semantic layer could look like in your context, get in touch with our team.
Read more
AI Success Starts With AI-Ready Data: What “Ready” Really Means
AI-Ready Data Series — Part 1 AI is everywhere right now. New copilots, assistants, agents, and automation promises appear almost weekly. But in practice, man...
Read moreGenAI Without Data Governance is Exposure: The Universal Semantic Layer
From Data Chaos to Trusted Intelligence There is no modern business without data. However, without shared meaning and governance, it’s an unstable asset. Ever...
Read more